Client outcomes
What the simulation
found.
Real engagement results. The non-obvious insight is always the one worth paying for.

Fintech · India · CS-011
Savings Habit Decay & AutoPay Churn
+41pts
Income predicted almost nothing about who churned. Identity around saving predicted everything.
Read case →

E-Commerce · Amazon · CS-012
The Keyword That Blocked Its Own Market
83%
One diet keyword suppressed 83% of the addressable audience. Nobody at the company had noticed.
Read case →
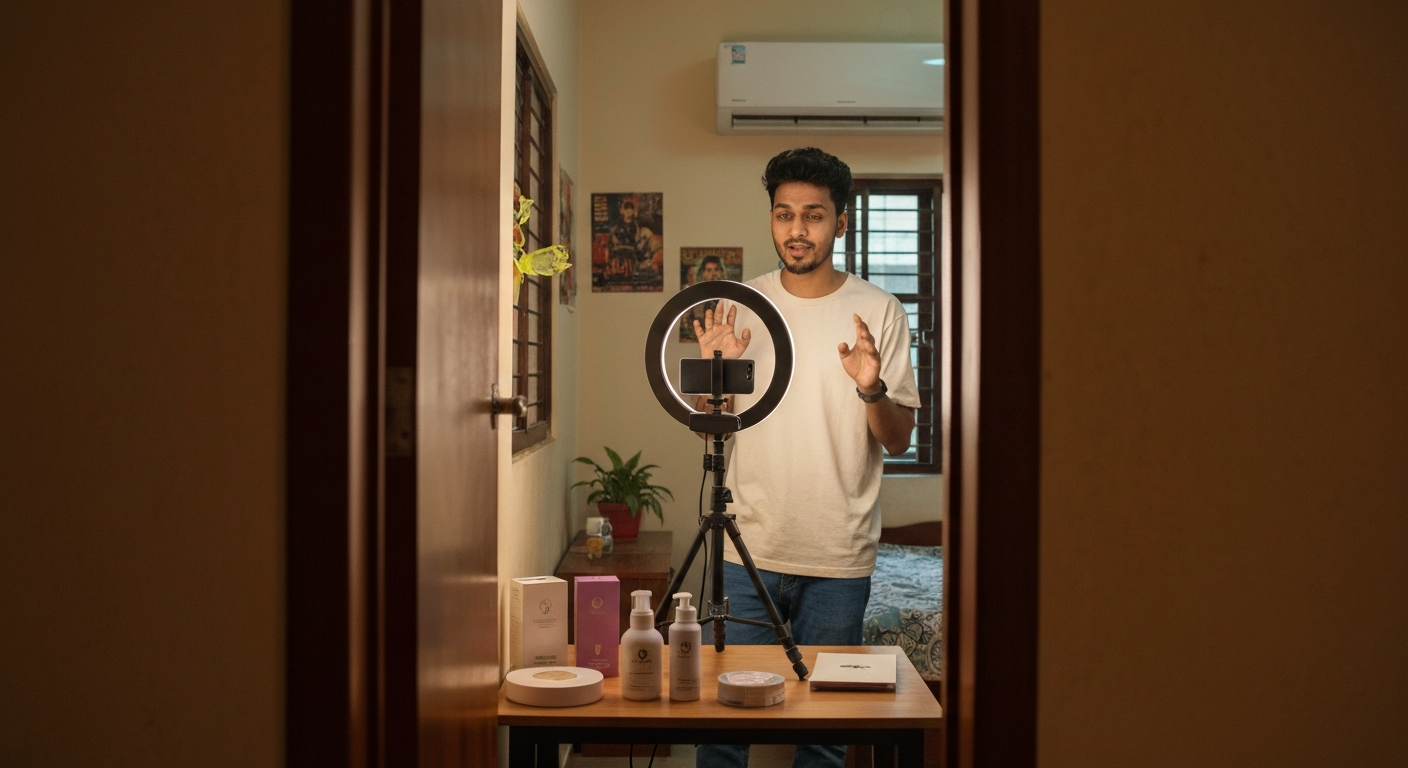
D2C · Creator Economy · CS-013
Creator Purchase Authority Audit
3×
The creator with 10% of the followers was converting 3× better. Reach is not authority.
Read case →

FMCG · Brand · CS-014
The Brand Name Ceiling
0/3
Brand architecture options tested. The category-defining name had become a psychological ceiling on expansion.
Read case →

Consumer Goods · India · CS-015
Tier 2/3 Market Entry — The Channel Nobody Budgets For
5 cities
Purchase ran through kirana networks and local trust — channels outside the brand's entire go-to-market plan.
Read case →